Vous n'êtes pas identifié(e).
- Contributions : Récentes | Sans réponse
#1 Re : Sécurité » Accès fonction dans schema public denied » 02/12/2020 14:55:18
Bonjour Julien et merci de votre réponse.
En réalité je l'ai fait :

Mais une fois que j'ai sauvegardé, le droit a aussitôt disparu :

#2 Sécurité » Accès fonction dans schema public denied » 02/12/2020 12:16:50
- Geo-x
- Réponses : 3
Bonjour @ tous.
J'essaie de donner accès à une fonction présente dans le schéma public au user myuser qui ne doit pas avoir accès à tout le schéma public .
Pour cela je lui ai donné accès à la fonction (ça a fonctionné sur d'autres fonctions)
Le problème c'est que lorsque l'utilisateur essaie d'utiliser cette dernière le message suivant apparaît :
ERROR: permission denied for schema public
LINE 1: SELECT public.myfunction(myinteger...Autre solution testée :
J'ai essayé à tout hasard de récupérer cette fonction et de l'intégrer à un schéma dont l'utilisateur est le propriétaire mais là, la fonction ne fonctionne plus du tout (il me dit que la fonction n'existe pas).
Merci de votre aide.
Geo-x
#3 Re : Sécurité » Problème de droit - WARNING : no privileges were granted » 01/12/2020 12:07:16
Ok c'est bon, pour information, j'ai attribué mon nouveau_user en tant que propriétaire sur les deux schémas à modifier.
De fait mon user_proprietaire historique qui hérite des droits du superuser, continue à pouvoir faire des ALTER sur ces mêmes schémas.
C'est donc une affaire résolu, merci beaucoup de votre précieuse aide.
Geo-x
#4 Re : Sécurité » Problème de droit - WARNING : no privileges were granted » 01/12/2020 11:28:02
Bonjour Guillaume.
En effet en faisant un
GRANT ROLE user_proprietaire TO nouveau_user;Ca fonctionne, sauf que maintenant nouveau_user a accès à beaucoup de choses, il ne me reste plus qu'à restreindre.
#5 Re : Sécurité » Problème de droit - WARNING : no privileges were granted » 25/11/2020 18:26:35
Merci pour cette précieuse requête.
Cependant comme je vous disais je cherche à voir qui a les droits pour attribuer par exemple le droit de faire des ALTER (sans mauvais jeu de mot niveau muscu) ou bien qui a accès à des fonctions.
Là c'est plus compliqué puisque mon besoin est le suivant :
> utiliser les fonctions du schéma dans lequel elle a accès + le schéma public
> Créer ou modifier des tabes et des vues sur un schéma spécifique
Ce n'est peut-être pas possible en fait.
#6 Re : Sécurité » Problème de droit - WARNING : no privileges were granted » 25/11/2020 15:29:25
Bonjour rjuju et merci de votre réponse.
Je vois le problème, comment pourrais-je faire pour visualiser les droits d'attribuer des droits (pas forcément table par table) ?
#7 Sécurité » Problème de droit - WARNING : no privileges were granted » 25/11/2020 12:38:51
- Geo-x
- Réponses : 7
Bonjour @ tous.
Je rencontre de grosses difficultés pour attribuer à un utilisateur le droit de création/modification de table et également au niveau de l'utilisation des fonctions, j'ai toujours ceci qui s'affiche lorsque j'essaie d'attribuer les droits :
WARNING: no privileges were granted for "unaccent_init"
WARNING: no privileges were granted for "unaccent_lexize"J'ai contrôlé les droits du rôle qui me semblent bon :
J'ai contrôlé les droits sur pg_database et j'ai ceci :
{group=CTc/group,monuser=c/group}Lorsque je regarde sur pg_class sur une table cible pour contrôler, j'ai ceci :
{admin=a*r*w*d*D*x*t*/monuser=arwdDxt/admin}De mon côté ce que je souhaite c'est que le user monuser puisse :
> utiliser les fonctions du schéma dans lequel elle a accès + le schéma public
> Créer ou modifier des tabes et des vues sur un schéma spécifique
Est-ce que vous auriez une idée de ce qui bloque ?
Merci d'avance de votre aide.
Geo-x
#8 Re : Général » Utilisation de PostgreSQL en mode NOsql » 23/11/2020 14:40:01
Merci de ce retour.
Oui en effet l'objet est sur plusieurs niveaux et est amené à être modifié.
Là je suis en train de faire un test ou mon objet serait :
{
"uuid": uuid,
"date_create": timestamp with time zone,
"date_start": timestamp with time zone,
"date_end": timestamp with time zone,
"statut": character varying,
"version": character varying,
"description": character varying,
"ref_externe": character varying,
"key_duck": character varying,
"type_data": jsonb{},
"type_object": jsonb{},
"timeline": jsonb{},
"document": jsonb{},
"sub_object": jsonb[]
}#9 Re : Général » Utilisation de PostgreSQL en mode NOsql » 23/11/2020 10:04:31
Bonjour Guillaume et merci de votre réponse.
Dans ce cas, il vaut mieux privilégier le format jsonb c'est ce qu'il me semblait :-)
Dans l'exemple explicité dans l'introduction du sujet, on peut remarquer des sous-sous-sous-sous-sous niveaux. En terme d'architecture, sur la documentation officielle, je ne vois pas spécialement d'optimisation requises. Ceci veut donc dire que je peux intégrer mes sous-niveaux directement dans un champ dès le niveau 2 ? Même si c'est un ARRAY ?
#10 Re : Général » Utilisation de PostgreSQL en mode NOsql » 22/11/2020 22:10:06
Bonsoir dverite.
Merci de cette traduction :-) En effet ça me parait pertinent.
Pour les json, en revanche, de ce que je comprends en utilisant des champs de type jsonb, l'indexation est automatique, cela rentre dans le champ de ce que vous précisez ? ( à savoir une modification de structure fou tout en l'air)
Merci
#11 Re : Général » Utilisation de PostgreSQL en mode NOsql » 19/11/2020 13:46:46
Bonjour @ tous.
Visiblement peu de gens utilisent Postgres comme une base NOsql (。◕‿◕。)
Juste pour avancer sur ce sujet, j'ai continué de lire la documentation et je suis tombé sur ce chapitre qui m'est apparu intéressant :
8.14.2. Concevoir des documents JSON efficacement
Représenter des données en JSON peut être considérablement plus flexible que le modèle de données relationnel traditionnel, qui est contraignant dans des environnements où les exigences sont souples. Il est tout à fait possible que ces deux approches puissent coexister, et qu'elles soient complémentaires au sein de la même application. Toutefois, même pour les applications où on désire le maximum de flexibilité, il est toujours recommandé que les documents JSON aient une structure quelque peu fixée. La structure est typiquement non vérifiée (bien que vérifier des règles métier de manière déclarative soit possible), mais le fait d'avoir une structure prévisible rend plus facile l'écriture de requêtes qui résument utilement un ensemble de « documents » (datums) dans une table.
Les données JSON sont sujettes aux mêmes considérations de contrôle de concurrence que pour n'importe quel autre type de données quand elles sont stockées en table. Même si stocker de gros documents est prévisible, il faut garder à l'esprit que chaque mise à jour acquiert un verrou de niveau ligne sur toute la ligne. Il faut envisager de limiter les documents JSON à une taille gérable pour réduire les contentions sur verrou lors des transactions en mise à jour. Idéalement, les documents JSON devraient chacun représenter une donnée atomique, que les règles métiers imposent de ne pas pouvoir subdiviser en données plus petites qui pourraient être modifiées séparément.Le problème, c'est que je ne suis pas certain de comprendre, concrètement, à quoi cela peut ressembler au final (surtout le terme de donnée atomique ఠ_ఠ )
Une idée ?
Merci de votre aide.
Geo-x
#12 Général » Utilisation de PostgreSQL en mode NOsql » 17/11/2020 21:59:08
- Geo-x
- Réponses : 7
Bonjour @ tous.
J'aurais aimé quelques conseils concernant les bases NOsql je m'explique.
Je cherche une technologie de base NOsql un peu "hybride" qui me donne les avantages d'une base NOsql (lecture/écriture de masse efficace, enregistrement d'objets simplifiés (array,json...)) et une partie des BDD relationnelles (facilitation de requêtage entre autre), et c'est tout naturellement que j'ai pensé à Postgres.
Voici le genre d'objet que j'ai aujourd'hui dans ma BDD NOsql "classique" :
{
"uuid",
"date_create",
"date_start",
"date_end",
"statut",
"version",
"description",
"ref_externe",
"key_duck",
"type_data": {
"uuid",
"code",
"description"
},
"type_object": {
"uuid",
"code",
"description"
},
"timeline": {
"day",
"month",
"year"
},
"document": {
"description",
"url"
},
"sub_object": [{
"uuid",
"number",
"type_datas": {
"uuid",
"code",
"description"
},
"type_objects": {
"uuid",
"code",
"description"
},
"number_sub",
"description",
"sub_sub_object_array": [{
"sub_sub_sub_object1_array": [{
"uuid",
"code",
"description"
},
...
],
"sub_sub_sub_object2_array": [{
"code",
"description",
"my_json": {
"uuid",
"code"
}
},
...
],
},
...
],
"sub_sub_object_json1": {
"uuid",
"code",
"libelle",
"segment_tva"
},
"sub_sub_object_json2": {
"uuid",
"code",
"description",
"sub_sub_sub_object_json": {
"sub_sub_sub_sub_object_json": {
"uuid",
"code",
"description"
},
"sub_sub_sub_sub_object_array": [{
"code",
"number"
},
...
],
},
}
},
...
]
}Sur ce type d'objet, j'ai besoin de pouvoir faire des recherches sur des objets imbriqués et donc d'avoir des indexations efficaces.
J'ai donc deux questions (pour commencer) :
1/ ce format là d'enregistrement est-il adapté à une base de données comme Postgres en mode NOsql ? (en gros à partir de sub_object on met l'objet dans une colonne jsonb)
2/ Vaut-il mieux privilégier des objets très imbriqués comme cela ou bien vaut-il mieux créer autant de tables qu'il y a de sous-objets ?
Merci de vos retours (et même s'il s'agit de retours d'expériences hors des deux questions, je suis évidemment preneur)
Geo-x
#13 PL/pgSQL » Détecter différents formats de date » 19/06/2020 10:37:13
- Geo-x
- Réponses : 1
Bonjour à tous.
J'ai une table contenant une colonne au format character varying() contenant deux différents formats (21/02/2014 09:56, 2014-02-27 15:05:00+00).
Je souhaiterais uniformiser ces dates en Timestamp With Time Zone mais pour cela il faudrait déjà que je puisse détecter les formats existants.
Comment puis-je requêter cela ?
Merci d'avance.
Geo-x
#14 PL/pgSQL » ORDER BY - Problème d'ordre » 08/06/2020 15:10:20
- Geo-x
- Réponses : 2
Bonjour @ tous.
Je cherche à ordonner les éléments suivants, à la façon d'un dictionnaire :

C'est à dire que dans ce cas j'aurais :
"dé"
"dé a"
"dé m"
"dé z"
"dép"
"dép a"
"dép m"
"dép z"
"départ"
"dépbrt"
"dépzrt"
Postgres me ressort l'ORDER BY de cette façon :

Comment puis-je faire ?
Merci
#15 Re : Général » Clé primaire ET clé étrangère ? » 06/02/2020 12:30:08
Ok merci, c'est ce qu'il me semblait.
Geo-x
#16 Général » Clé primaire ET clé étrangère ? » 06/02/2020 11:21:51
- Geo-x
- Réponses : 4
Bonjour à tous.
J'ai une question d'architecture sur mes bases Postgres.
J'ai les tables suivantes :
Table A {ID / Libelle}
Table B {ID / Libelle}
Un lien est possible entre les deux tables car les identifiants (ID) peuvent être identiques.
Comme dois-je déclarer mes contraintes ? Actuellement j'ai déclaré des clés primaires sur chacune des tables, mais en vérité, elles sont aussi les clés étrangères l'une de l'autre, est-ce possible de déclarer ces ID clés primaires et étrangères ?
Merci.
Geo-x
#17 Re : Optimisation » Optimisation des tables de joinutre » 23/12/2019 15:20:31
Bonjour rjuju et merci de votre réponse !
Oui c'est tout à fait ça, j'ai bien une clé primaire basée sur (id_table_a, id_table_b), c'est bien ce qui me semblait que la solution bleue n'était pas forcément utile.
Merci beaucoup et bonnes fêtes de fin d'année.
Geo-x
#18 Optimisation » Optimisation des tables de joinutre » 23/12/2019 14:23:32
- Geo-x
- Réponses : 3
Bonjour.
J'ai une question à laquelle je ne trouve pas de réponse dans la documentation.
J'ai un Postgres 9.6 et j'ai entre autre des tables de liaison. Je voulais savoir pour ces tables de liaison s'il était dans les habitudes/nécessaire/ou au contraire contre performant d'ajouter un identifiant unique :
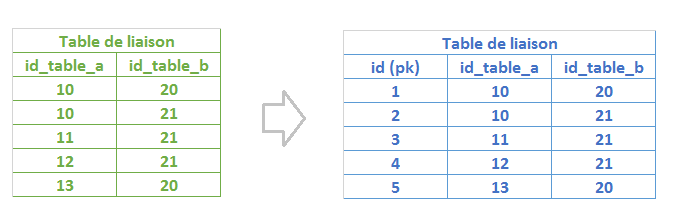
Merci de votre aide.
Geo-x
#19 Re : Général » Deadlocks timeout » 15/11/2019 13:08:01
D'accord merci, ça répond à une bonne partie de ma question :-)
#20 Général » Deadlocks timeout » 15/11/2019 11:13:23
- Geo-x
- Réponses : 2
Bonjour.
Je rencontre des problèmes de timeout sur mes deadlocks lors d'une insertion massive de données (visiblement parce que le trigger en cours n'a pas terminé son travail) :
********************************************************************************
Message : ERROR: deadlock detected
Detail: Process 17067 waits for ShareLock on transaction 304743; blocked by process 17058.
Process 17058 waits for ShareLock on transaction 304747; blocked by process 17067.
Hint: See server log for query details.
Where: while locking tuple (59,65) in relation "intervention"J'ai donc souhaité modifier ma valeur max de deadlock_timeout dans le pg_hba.conf mais je vois que la valeur n'est pas renseignée (par conséquent j'en déduis que la valeur s'adapte au besoin) :
Nom deadlock_timeout
Valeurs
Valeurs autorisées 1-2147483647
Adaptabilité true
Source engine-default
Type d'application dynamic
Type de données integer
Description (ms) Sets the time to wait on a lock before checking for deadlock.Qu'est ce qui pourrait être à l'origine du problème ? Faut-il que je renseigne une valeur ?
#21 Re : PL/pgSQL » Conservation des 80000 derniers enregistrements » 31/07/2018 11:03:51
Oui le NOT IN fonctionne, c'est juste que j'avais observé par le passé une meilleur performance avec le NOT EXISTS
#22 PL/pgSQL » Conservation des 80000 derniers enregistrements » 31/07/2018 10:55:56
- Geo-x
- Réponses : 3
Bonjour @ tous.
J'ai une table dans laquelle je souhaiterais conserver les 80000 derniers enregistrements (et donc supprimer quotidiennement tous les enregistrements < aux 80000 derniers enregistrements).
Pour cela je souhaite faire une requête du type :
DELETE FROM matable l WHERE NOT EXISTS (SELECT uuid FROM matable r WHERE l.uuid = r.uuid ORDER BY integration_date ASC LIMIT 80000)mais j'ai visiblement du mal à utiliser le NOT EXISTS puisqu'aucun enregistrement n'est pris en compte.
Avez-vous une idée sur comment reformuler cette requête ?
Merci de votre aide.
Geo-x
#23 Général » Différence entre OID et UUID » 25/06/2018 12:59:27
- Geo-x
- Réponses : 1
Bonjour @ tous.
J'ai du mal à comprendre la différence entre un OID et un UUID.
Pour le moment la seule différence que je vois c'est le format d'écriture de l'identifiant qui est différente, mais l'OID peut-il par exemple se substituer à l'UUID (sachant que l'OID est natif dans Postgres là ou l'UUID nécessite une extension).
Merci de vos éclairages.
Geo-x
#24 Re : Général » Construction de bases avec vues modifiables » 27/02/2018 19:09:58
Bonjour Michel et merci de votre retour.
Oui c'est bien comme cela que j'ai l'habitude de faire, comme indiqué ce que je souhaite c'est avoir des retours d'expérience sur cette méthode, ou bien s'il existe d'autres façons de faire auquel cas lesquelles ?
Geo-x
#25 Re : Général » Construction de bases avec vues modifiables » 27/02/2018 18:42:42
Et bien déjà félicitations pour votre livre, c'est très complet et très bien fait.
Pour essayer de compléter mes propos, l'objectif de cette futur base sera notamment de permettre à un utilisateur lambda d'accéder à des informations réunies sous forme de tableau (ex. tableau de gestion d'indicateurs) ou bien sous forme cartographique (ex. cartographie des documents d'urbanisme).
Par exemple si je prend ce MCD :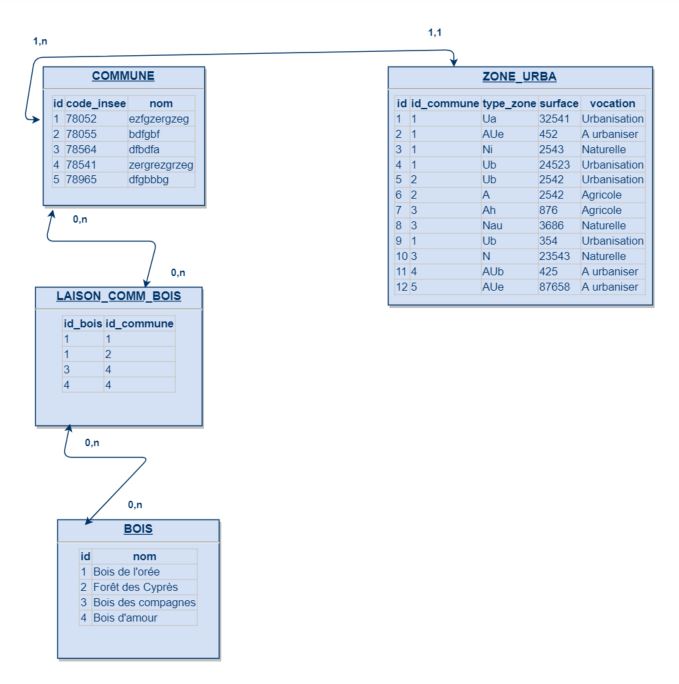
Je peux construire un tableau utilisable par un logiciel tiers :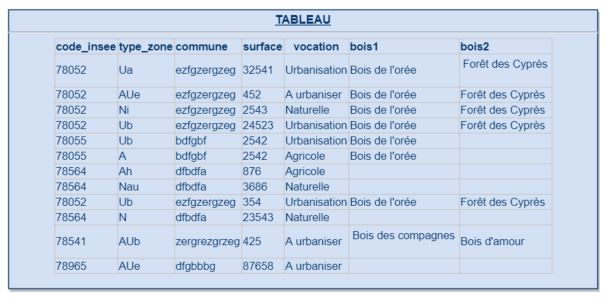
Problème si je souhaite que ce tableau soit modifiable si celui-ci est généré via une vue, comment puis-je faire ?
Geo-x