Vous n'êtes pas identifié(e).
- Contributions : Récentes | Sans réponse
#1 Général » Opération sur des timestamp » 02/06/2010 12:01:36
- etpaf
- Réponses : 1
Salut,
J'ai un petit problème d'opération sur des dates dans une requête, je viens donc faire appel à vos lumières.
J'ai dans une table la date d'arrivée d'une voiture (timestamp) dans un parking, je dispose aussi dans la même table du nombre de minutes pendant lequel le véhicule y est resté.
Je devrais avoir aussi la date de sortie mais suite à un bug, elle semble avoir disparu. (champ à null)
J'ai besoin de savoir un véhicule était présent dans un intervalle de temps donné mais je sèche...
J'avais pensé à un
SELECT voiture FROM t_vh
WHERE heure_de_référence between heure_d_arrivee and heure_d_arrivee + intervale temps_passe;
Mais ça ne fonctionne pas, quelqu'un voit le pourquoi?
#2 Re : Général » Serveur muet » 26/04/2010 12:10:53
Bonjour,
Concernant les logs, je vous propose de jouer les commandes suivante :
mkdir /pghome/data/pg_log (pghome chez moi est /usr/local/pgsql)
chown postgres:postgres /pghome/data/pg_log -R
Et ajouter ceci dans la fin de votre fichier /pghome/data/postgresql.conf
#Paramètrage des logs
log_destination = 'stderr'
redirect_stderr = on
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_rotation_age = 1d
log_rotation_size = 100MB
client_min_messages = warning
log_connections = on
log_disconnections = on
Relancez ensuite postgres et postez le contenu du fichier qui sera dans le répertoire /pghome/data/pg_log il sera sans doute plus facile de vous répondre.
#3 Re : Général » Migration de PostgreSQL 8.2 vers PostgreSQL 8.4 » 20/04/2010 16:29:02
Merci pour cette rapide réponse.
Slony est un produit auquel je m'étais intéressé mais que j'ai vite laissé tombé au vue de sa complexité.
Je crois que je vais maintenant devoir m'y replonger... ![]()
Si j'ai bien compris l'astuce, il faut un dump structurel des DB, un Slony configuré et le remplissage des données sera "automatique"?
#4 Général » Migration de PostgreSQL 8.2 vers PostgreSQL 8.4 » 20/04/2010 15:57:36
- etpaf
- Réponses : 3
Bonjour,
Dans la documentation, j'ai pu lire que le seul moyen de passer d'une version 8.2 vers une 8.4 est de procéder par le biais d'un dump.
Il faut dumper la base de données sur le serveur 8.2 et la restaurer sur le 8.4, malheureusement, cette opération prend beaucoup de temps.
La base a migrer fait 35 giga et est accédée en permanence par des utilisateurs qui y font de la lecture et de l'écriture.
Le temps de restauration du dump est approximativement de 6h et le temps pour le réaliser est de près de 2h.
Existe-t-il une solution plus rapide?
Merci.
#5 Re : Installation » Montage NFS ou ISCSI » 29/03/2010 12:16:14
Merci pour cette rapide réponse...
J'ai tourné et retourné la documentation dans tous les sens et la personne qui fait les traduction (google?) n'a pas fait un texte des plus français... (ou peut être est-ce moi qui mélange les termes?)
Existe-t-il une autre source de renseignements?
#6 Installation » Montage NFS ou ISCSI » 29/03/2010 11:44:52
- etpaf
- Réponses : 2
Salut,
Je vais installer PostgreSQL sur un Serveur RHEL 5.4.
La base de données doit se trouver sur un SAN, j'aimerais savoir quelle est la manière la plus judicieuse pour faire le montage : NFS ou ISCSI (les 2 sont possibles).
Est-ce qu'il y a des différences de stabilité ou de performances?
Je n'ai pas trouvé de documents sur le site de postgres à ce sujet.
D'avance merci.
#7 Re : Réplication » Erreur CETFATAL - Warm Standby » 23/02/2010 17:00:34
Salut,
Si j'ai bien compris m
La 8.5 permet de se connecter en lecture seule sur la base qui est en écoute, c'était impossible avant (en tout cas, certainement impossible en 8.2).
La version 9 est le nom "commercial" de la 8.5, renommé car elle contient beaucoup d'apport.
#8 Re : Optimisation » Requète (très, très) lente... » 21/02/2010 09:34:50
Merci pour votre aide.
Je vais donc laisser autovacuum_analyze_scale_factor = 0.2 dans mon fichier de propriété.
Je ferai aussi une ligne dans pg_autovacuum pour chacune des grosses tables manipulées par l'application avec scale_factor à 0 et fréquence d'analyse et vacuum respectivement à 5000 et 10.000 lignes modifiées.
J'ai par contre abaissé à 100 le set statistics car j'ai constaté une grosse montée de l'utilisation de mon file system avec le set statistics à 500 (nettement moindre mais tout aussi performant à 100).
#9 Re : Optimisation » Requète (très, très) lente... » 19/02/2010 14:59:29
Je ne sais pas trop, je n'ai pas développé l'application...
Ca a une importance?
#10 Re : Optimisation » Requète (très, très) lente... » 19/02/2010 11:57:20
Bonjour,
La différence est énorme, avec un SET STATISTICS à 500 sur mon index, l'analyse est 2 fois plus lent mais la requête ne prend plus que 469ms.
Un tout grand merci pour le coup de main.
Une dernière question, concernant l'analyse, puis-je mettre autovacuum_analyze_scale_factor à 0?
#11 Re : Optimisation » Requète (très, très) lente... » 18/02/2010 15:53:06
Merci encore...
Chose étrange, après avoir lancé 1 analyse, ça s'accélère mais...
Unique (cost=1940027.55..1963256.44 rows=1548593 width=36) (actual time=188216.157..188225.939 rows=858 loops=1)
-> Sort (cost=1940027.55..1943899.03 rows=1548593 width=36) (actual time=188216.148..188219.323 rows=867 loops=1)
Sort Key: lm_action.origin, lm_action.entry_key, lm_action.pkey, lm_action.creation_ts, lm_action.polhid
-> Hash Join (cost=896687.13..1744515.62 rows=1548593 width=36) (actual time=171962.153..188211.231 rows=867 loops=1)
Hash Cond: (lm_status.action_key = lm_action.pkey)
-> Bitmap Heap Scan on lm_status (cost=163653.01..769996.01 rows=10693207 width=8) (actual time=28388.613..133203.947 rows=10744023 loops=1)
Recheck Cond: (status = ANY ('{2,1}'::integer[]))
Filter: (inactif_uid IS NULL)
-> Bitmap Index Scan on idx_lm_status_status (cost=0.00..160979.71 rows=10732560 width=0) (actual time=28314.001..28314.001 rows=10857831 loops=1)
Index Cond: (status = ANY ('{2,1}'::integer[]))
-> Hash (cost=633064.22..633064.22 rows=4921592 width=36) (actual time=16.765..16.765 rows=1215 loops=1)
-> Bitmap Heap Scan on lm_action (cost=90336.65..633064.22 rows=4921592 width=36) (actual time=1.112..8.834 rows=1215 loops=1)
Recheck Cond: (entry_key = ANY ('{3974400,3958028,3940355,3940309,3917969,3911509,3888821,3870523,3862873,3816029,3804693,3799560,3799546,3799542,3794777,3782636,3771277,3771233,3771222,3764226,3764147,3764136,3764130,3764125,3764121,3754407,3754396,3748869,3744775,3744774,3744772,3744771,3744764,3744758,3744742}'::bigint[]))
-> Bitmap Index Scan on idx_lm_action_entry_key (cost=0.00..89106.25 rows=4921592 width=0) (actual time=1.058..1.058 rows=1215 loops=1)
Index Cond: (entry_key = ANY ('{3974400,3958028,3940355,3940309,3917969,3911509,3888821,3870523,3862873,3816029,3804693,3799560,3799546,3799542,3794777,3782636,3771277,3771233,3771222,3764226,3764147,3764136,3764130,3764125,3764121,3754407,3754396,3748869,3744775,3744774,3744772,3744771,3744764,3744758,3744742}'::bigint[]))
Total runtime: 137230.291 ms
Le nombre de ligne rapportées ne change pas, les données sont pourtant récupérées plus rapidement (mise en cache?).
#12 Re : Optimisation » Requète (très, très) lente... » 18/02/2010 14:12:44
Merci pour ces renseignements...
Je vais encore abuser mais comment fait-on une configuration particulière pour une table?
#13 Re : Optimisation » Requète (très, très) lente... » 18/02/2010 12:12:51
Je viens de lancer un analyse depuis pg_admin sur les 2 tables et je passe maintenant à 137000ms, il y a effectivement un mieux.
Je croyais que Postgres gérais les analyses et vacuum sur base du fichier postgresql.conf, le mien serait-il mal configuré?
J'utilise ceci :
autovacuum = on
autovacuum_naptime = 60
autovacuum_vacuum_threshold = 250
autovacuum_analyze_threshold = 125
autovacuum_vacuum_scale_factor = 0.4
autovacuum_analyze_scale_factor = 0.2
vacuum_cost_delay = 0
vacuum_cost_page_hit = 1
vacuum_cost_page_miss = 10
vacuum_cost_page_dirty = 20
vacuum_cost_limit = 200
Manque-t-il des paramètres?
#14 Re : Optimisation » Requète (très, très) lente... » 18/02/2010 09:47:20
Bonjour,
Merci pour l'intérêt porté à ma question.
L'explain analyse donne ceci :
Unique (cost=1900115.33..1919800.62 rows=1312353 width=36) (actual time=327436.701..327446.455 rows=855 loops=1)
-> Sort (cost=1900115.33..1903396.21 rows=1312353 width=36) (actual time=327436.691..327439.849 rows=864 loops=1)
Sort Key: lm_action.origin, lm_action.entry_key, lm_action.pkey, lm_action.creation_ts, lm_action.polhid
-> Hash Join (cost=886494.66..1735996.83 rows=1312353 width=36) (actual time=310684.445..327431.949 rows=864 loops=1)
Hash Cond: (lm_status.action_key = lm_action.pkey)
-> Bitmap Heap Scan on lm_status (cost=176955.22..794709.68 rows=11597756 width=8) (actual time=100966.826..279975.553 rows=10740857 loops=1)
Recheck Cond: (status = ANY ('{2,1}'::integer[]))
Filter: (inactif_uid IS NULL)
-> Bitmap Index Scan on idx_lm_status_status (cost=0.00..174055.78 rows=11656037 width=0) (actual time=100895.813..100895.813 rows=10854635 loops=1)
Index Cond: (status = ANY ('{2,1}'::integer[]))
-> Hash (cost=632301.26..632301.26 rows=3802495 width=36) (actual time=73.277..73.277 rows=897 loops=1)
-> Bitmap Heap Scan on lm_action (cost=89929.49..632301.26 rows=3802495 width=36) (actual time=0.909..58.674 rows=897 loops=1)
Recheck Cond: (entry_key = ANY ('{3974400,3958028,3940355,3940309,3917969,3911509,3888821,3870523,3862873,3816029,3804693,3799560,3799546,3799542,3794777,3782636,3771277,3771233,3771222,3764226,3764147,3764136,3764130,3764125,3764121,3754407,3754396,3748869,3744775,3744774,3744772,3744771,3744764,3744758,3744742}'::bigint[]))
Filter: (inactif_uid IS NULL)
-> Bitmap Index Scan on idx_lm_action_entry_key (cost=0.00..88978.86 rows=4917019 width=0) (actual time=0.853..0.853 rows=1215 loops=1)
Index Cond: (entry_key = ANY ('{3974400,3958028,3940355,3940309,3917969,3911509,3888821,3870523,3862873,3816029,3804693,3799560,3799546,3799542,3794777,3782636,3771277,3771233,3771222,3764226,3764147,3764136,3764130,3764125,3764121,3754407,3754396,3748869,3744775,3744774,3744772,3744771,3744764,3744758,3744742}'::bigint[]))
J'ai aussi vérifié les vacuum et le dernier date de moins de 12h.
Existe-t-il un petit programme qui permette d'interpréter les valeurs retournées par l'explain analyse facilement?
#15 Re : Installation » initDB erreur » 17/02/2010 17:45:36
Bonjour,
Renommez le répertoire data de l'arborescence /opt/var/pgsql/data et relancez l'installation.
Ca devrait fonctionner.
#16 Optimisation » Requète (très, très) lente... » 17/02/2010 10:31:30
- etpaf
- Réponses : 15
Bonjour à tous,
J'ai une requête qui est franchement lente et je ne comprends pas le pourquoi...
Ma config : serveur dédié, postgresql 8.2.14 sous RHEL 4.4. (8giga ram, disque en raid 10)
La requète :
SELECT DISTINCT lm_action.entry_key , lm_action.pkey , lm_action.creation_ts , lm_action.origin , lm_action.polhid
FROM lm_action
INNER JOIN lm_status ON (lm_action.pkey=lm_status.action_key )
WHERE lm_action.inactif_uid is null AND lm_status.status IN (2 , 1 )
AND lm_status.inactif_uid is null
AND lm_action.entry_key in (3974400 , 3958028 , 3940355 , 3940309 , 3917969 , 3911509 , 3888821 , 3870523 , 3862873 , 3816029 , 3804693 , 3799560 , 3799546 , 3799542 , 3794777 , 3782636 , 3771277 , 3771233 , 3771222 , 3764226 , 3764147 , 3764136 , 3764130 , 3764125 , 3764121 , 3754407 , 3754396 , 3748869 , 3744775 , 3744774 , 3744772 , 3744771 , 3744764 , 3744758 , 3744742 )
ORDER BY origin;
Son temps d'exécution : 446723 ms pour rapporter 851 lignes.
Les tables :
CREATE TABLE lm_action
(
pkey bigserial NOT NULL,
entry_key bigint,
regrouping_key bigint,
creation_ts timestamp without time zone,
origin timestamp without time zone,
polhid integer,
inactif_uid bigint,
CONSTRAINT lm_action_pkey PRIMARY KEY (pkey),
CONSTRAINT lm_action_fk FOREIGN KEY (entry_key)
REFERENCES lm_entry (pkey) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT lm_action_fk1 FOREIGN KEY (regrouping_key)
REFERENCES lm_entry_regrouping (pkey) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE NO ACTION
)
WITH (
OIDS=TRUE
);
ALTER TABLE lm_action OWNER TO arthur;
CREATE INDEX idx_lm_action_entry_key
ON lm_action
USING btree
(entry_key);
CREATE TABLE lm_status
(
pkey bigserial NOT NULL,
entry_key bigint,
action_key bigint,
regrouping_key bigint,
status smallint,
creation_ts timestamp(0) without time zone NOT NULL,
polhid integer NOT NULL,
inactif_uid bigint,
origin timestamp without time zone,
CONSTRAINT lm_status_pkey PRIMARY KEY (pkey),
CONSTRAINT lm_status_fk FOREIGN KEY (entry_key)
REFERENCES lm_entry (pkey) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT lm_status_fk1 FOREIGN KEY (regrouping_key)
REFERENCES lm_entry_regrouping (pkey) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT lm_status_fk2 FOREIGN KEY (action_key)
REFERENCES lm_action (pkey) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE NO ACTION,
CONSTRAINT lm_status_fk3 FOREIGN KEY (inactif_uid)
REFERENCES lm_delete_data (pkey) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE NO ACTION
)
WITH (
OIDS=TRUE
);
ALTER TABLE lm_status OWNER TO arthur;
CREATE INDEX idx_lm_status_action_key
ON lm_status
USING btree
(action_key);
CREATE INDEX idx_lm_status_entry_key
ON lm_status
USING btree
(entry_key);
CREATE INDEX idx_lm_status_origin
ON lm_status
USING btree
(origin);
CREATE INDEX idx_lm_status_status
ON lm_status
USING btree
(status);
CREATE INDEX lm_status_idx2
ON lm_status
USING btree
(regrouping_key);
Le plan d'exécution :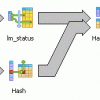
Je suis assez perplexe car je ne dépasse pas les 2 secondes pour les autres requêtes sur ma DB.
Pour configurer postgresql.conf, j'ai utilisé pg_tune (légèrement adapté).
Est-ce que l'un d'entre vous voit la cause de ces lenteurs?
D'avance merci pour votre aide.
#17 Optimisation » Requète extrèmement lente. » 03/02/2010 18:44:24
- etpaf
- Réponses : 1
Salut,
J'ai un petit problème de lenteur qui me pose des soucis.
Lorsque j'exécute une requête sur une grosse table de mon application (8.000.000 de lignes, 2,6giga) j'obtiens une liste d'identifiants en à peine quelques millisecondes (+/-40).
Si j'utilise le résultat de ma requête dans une seconde requête (la 50aine de identifiants) dans la clause "where id in (ma liste)" j'ai les résultats qui ressortent aussi en millisecondes (+/-500).
(table 2= 3.000.000 de lignes et 1,2 giga). Jusque là, vous me direz que c'est impeccable.
Mais si j'essaie de faire une jointure entre les 2 tables pour récupérer le même résultat que celui retourné par la seconde requête, le temps d'exécution dépasse les 5 minutes si j'utilise un "inner join" et 1 minute si je passe par un "where table1.id=table2.id".
Quelqu'un voit où se situe le problème?
Je n'ai aucun ennuis de performance à quelqu'autre niveau.
J'utilise postgres 8.2.14 sur centos 5.3, il s'agit d'un serveur dédié (6giga de ram, raid 10).
#18 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 16:21:41
Les 2 OS sont en 32 bits (les CPU permettent le 64 mais le client avait déjà des licences pour du 32).
Je re-essaierai dès que possible l'intégralité de la procédure (de l'archivage du data à sa restauration dès que possible mais le client dispose d'une DB de 35 giga et c'est coton à copier...)
En tout cas, merci pour les avis...
#19 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 15:26:11
J'utilise la même archive sur les 2 serveurs, c'est assez étrange et plutôt difficile à justifier auprès d'un client.
Surtout que mon employeur a du pas mal batailler pour faire accepter PostgreSQL...
#20 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 12:50:58
2 tentatives sur l'opteron et 2 fois le même résultat...
Vous parlez d'erreur temporaire, s'agit-il d'une heure légèrement différentes sur les 2 serveurs?
#21 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 12:15:30
C'est ce que j'ai pensé au début mais je restaure mes bases via un script et c'est ce même script qui m'a permis d'avoir une copie fonctionnelle sur l'autre serveur Intel.
#22 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 11:46:33
Je viens de comparer les 2 fichiers de log et ils sont identiques, au nom des machines près...
Ce qui me semble plus étrange, c'est que j'ai pu restaurer ce data sur un autre serveur intel, avec postgres 8.2.14 et je n'ai pas le moindre soucis de séquence.
Je suis assez perplexe, les machines sont fort semblables (sauf cpu). Les partitions sont en ext3 sur les 3 machines, c'est assez inattendu...
#23 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 10:03:39
Effectivement, c'est une 8.2.6 mais depuis l'installation de ce client (3ans) nous sommes passé à la 8.2.12 (les lignes de commande viennent de ma dernière installation.)
Je n'avais pas pensé aux fichiers de log de l'installation, merci du conseil.
#24 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 09:30:45
J'ai utilisé gcc dans les 2 cas et compilé comme suit :
tar –xjvf postgresql-8.2.12.tar.bz2
cd /root/install/postgresql-8.2.12
./configure
make
make install
#25 Re : Réplication » Copie du répertoire pg_data et perte de séquences » 05/11/2009 08:43:39
Je ne sais pas si ça a ou non son importance mais je n'installe jamais postreSQL via package (rpm ou autre) je le compile toujours sur la machine.